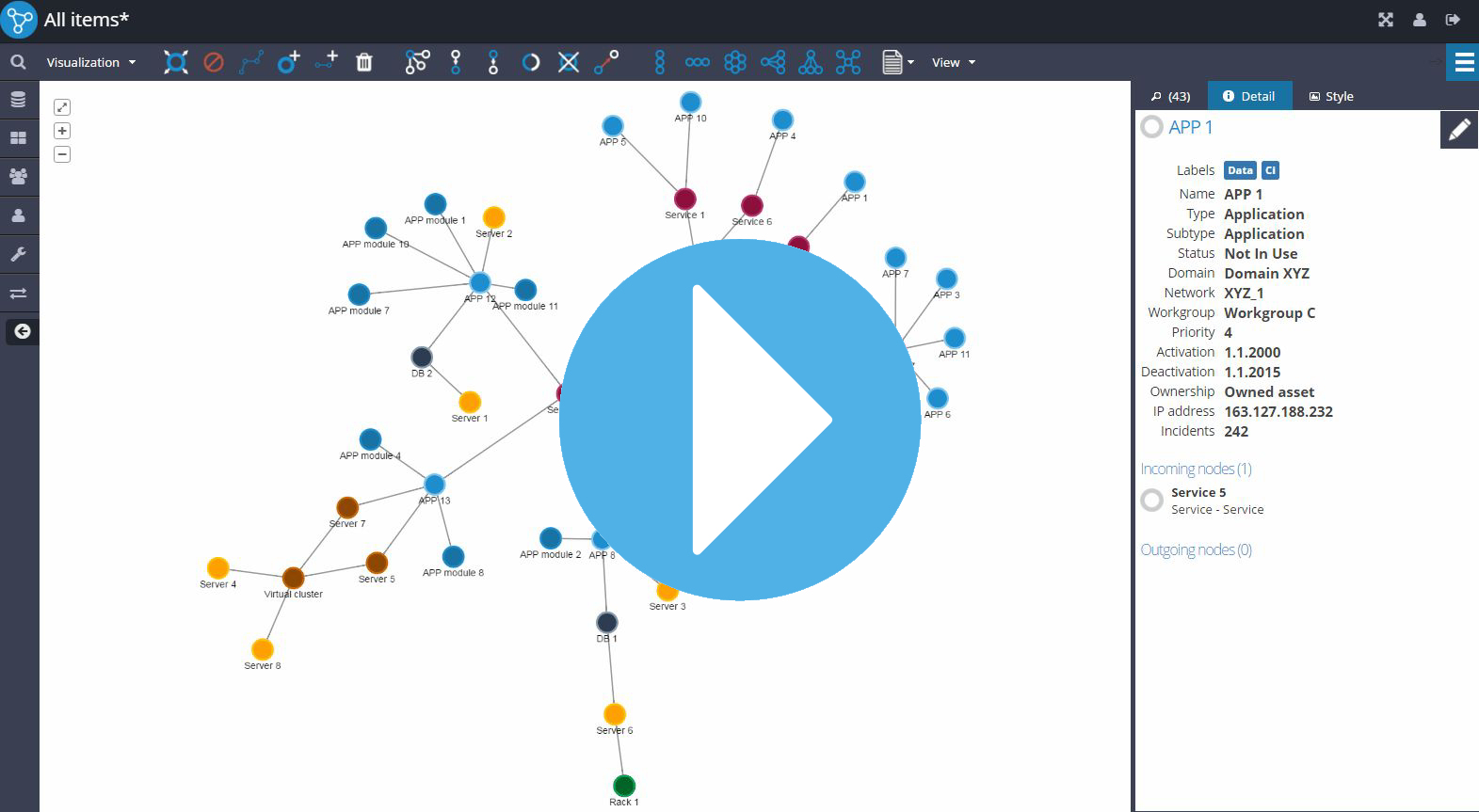
Visualization
Powerful HTML5 based graph visualizations with cytoscape.js library works with every major browser and platform
Graph DB
Graphlytic supports the world's leading graph database Neo4j which enables us to give you fantastic performance
Analytics
Look for patterns in your data with easy to use layouts, filtering or mapping data to visual properties like color or size
Scheduled Jobs
With Jobs it's easy to write and schedule your own scripts for importing data, searching patterns (with Cypher or Gremlin), and sending emails
Collaboration
Data analysis doesn't have to be a lonely job. Collaborate with other users and share your findings or export images and data
Business Solutions
Contact us if you are interested in using Graphlytic in specific business cases. We are happy to help you with the setup