Search Settings
Permissions needed: Settings management
This is a global setting. Changes will affect all users.
Table of Contents
Everything regarding the fulltext search can be configured in several places in the application:
Queries page - open the widget with the "Search Settings" button located in the header buttons.
Visualization page - open the widget with the cogs icon next to the search field
Application Setting page - open the widget with the "Configure fulltext search" button in the Graph Connections panel.
You can see the Search Settings widget in the picture below.
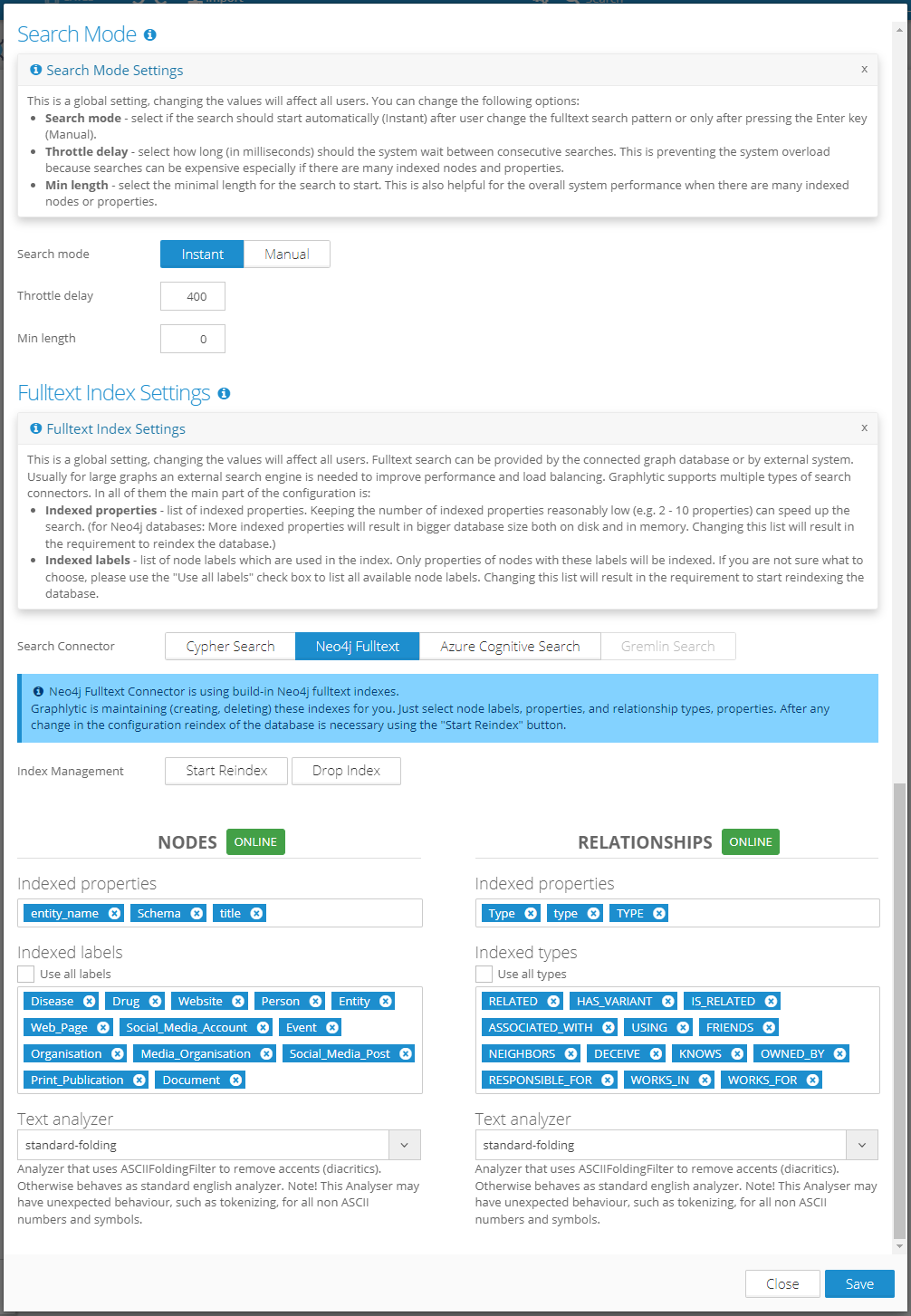
1. Search Mode Settings
This is a global setting, and changing the values will affect all users. You can change the following options:
Search mode - select if the search should start automatically (Instant) after the user changes the fulltext search pattern or only after pressing the Enter key (Manual).
Throttle delay - select how long (in milliseconds) should the system wait between consecutive searches. This prevents system overload because searches can be expensive especially if there are many indexed nodes and properties.
Min length - select the minimal length for the search to start. This is also helpful for the overall system performance when there are many indexed nodes or properties.
2. Fulltext Index Settings
This is a global setting, and changing the values will affect all users.
Graphlytic supports multiple Search Connectors. Every Search Connector can be used with different graph DB. See the table below to find the best combination for you.
Search Connector | Supported Graph DB | Notes |
|---|---|---|
Cypher Search | All graph DBs with Cypher support (Neo4j, Memgraph, …). | No external search engine is used and search is performed directly in the graph DB using pure Cypher value matching. This is a very basic search option with multiple limitations:
|
Neo4j Fulltext | Only Neo4j graph DB. | Uses the built-in Lucene search engine in Neo4j. This is the go-to setting when you are using Neo4j DB. |
Gremlin Search | All graph DBs with Gremlin support (Cosmos DB, Apache TinkerPop, …). | No external search engine is used and search is performed directly in the graph DB using pure Gremlin value matching. This is a very basic search option with multiple limitations:
|
Azure Cognitive Search | All graph DBs. Mainly for Cosmos DB. | Uses Azure Cognitive Search as an external search engine. Data has to be periodically imported into the Azure Cognitive Search service to ensure consistency between your graph DB and search indexes (Graphlytic is not doing this out of the box, the connection and data importing have to be done by the user). This search connector is best with Cosmos DB because Azure has multiple tools how to easily connect Cosmos DB and Azure Cognitive Search. |
2.1. Cypher Search
Search is performed directly in the graph DB using pure Cypher value matching. This is a very basic search option with multiple limitations:
full-scan of the graph is performed - can be very slow on larger graphs
case-sensitive search - values have to be entered precisely as they are stored in the graph
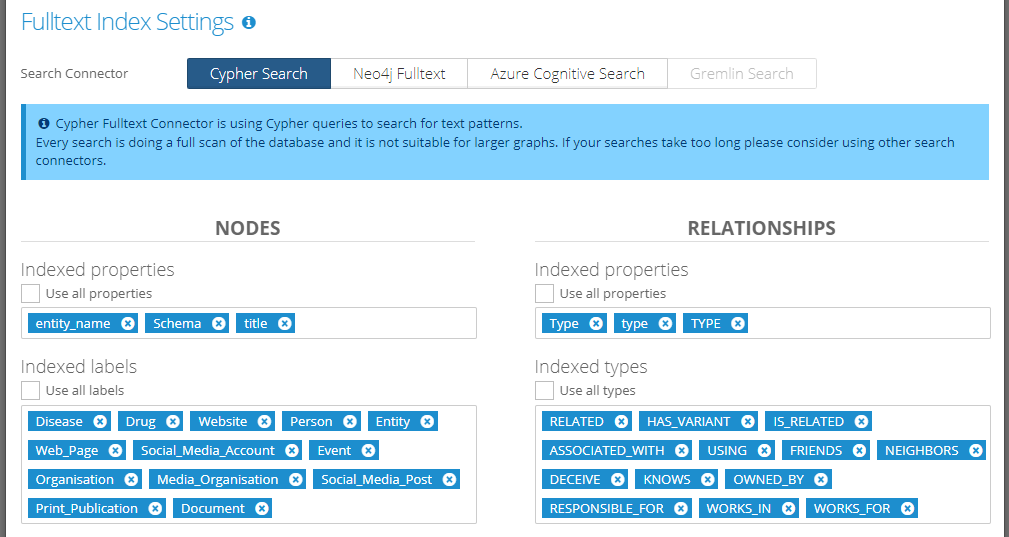
Parts of the configuration:
Indexed properties - list of properties used in the search query. Please choose the list carefully. Keeping the number of indexed properties reasonably low (e.g. 2 - 10 properties) can speed up the search.
The checkbox “Use all properties” can be used to automatically search using all properties in the graph.
Indexed labels - list of node labels that are used in the search query. Only properties of nodes with these labels will be searched.
The checkbox “Use all labels” can be used to automatically search using all node labels in the graph.
Indexed types - list of relationship types that are used in the search query. Only properties of relationships with these types will be searched.
The checkbox “Use all types” can be used to automatically search using all relationship types in the graph.
2.2. Neo4j Fulltext
Uses the built-in Lucene search engine in Neo4j. This is the go-to setting when you are using Neo4j DB.
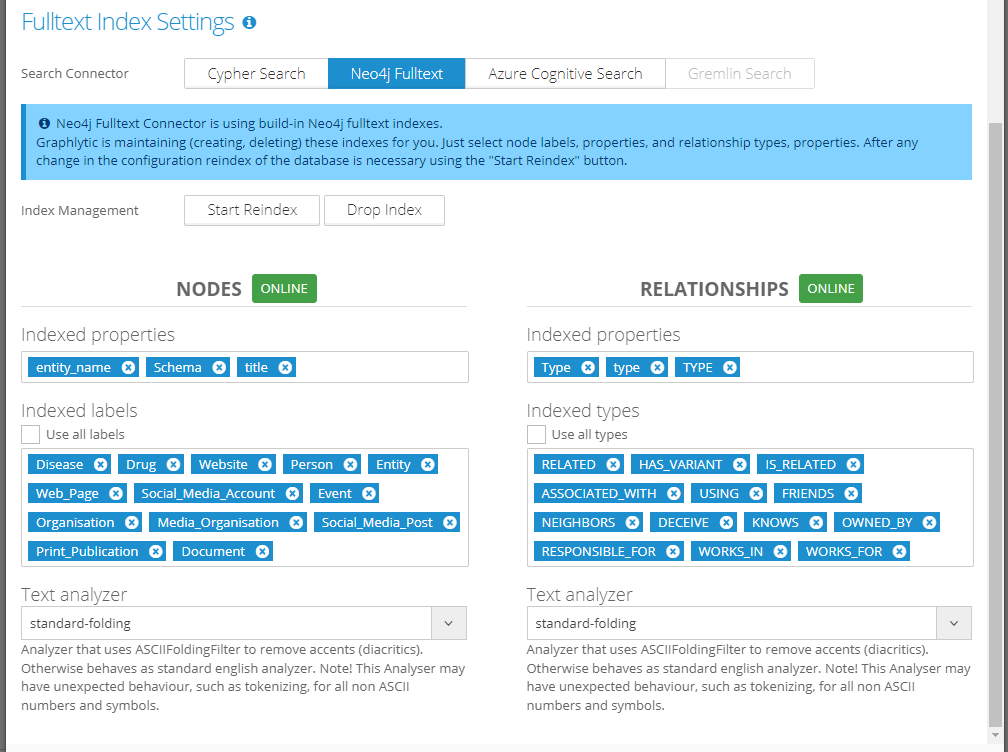
Parts of the configuration:
Index Management - buttons for Neo4j index management.
“Start Reindex” - recreates the Neo4j indexes (gl_fulltext_node_index and gl_fulltext_relationship_index) based on the current configuration.
“Drop Index” - deletes Neo4j indexes created by Graphlytic.
Status - shows the current Indexer state. The ONLINE is the default state when everything is OK.
Progress - Progress of reindexing. If the value is 0% the index is not created. If the value is 100% and the status is "Online" then the index is created and ready to be used.
Indexed properties - list of indexed properties. Please choose the list carefully. More indexed properties will result in a bigger database size both on disk and in memory. Keeping the number of indexed properties reasonably low (e.g. 2 - 10 properties) can also speed up the search. Changing this list will result in the requirement to reindex the database.
Indexed labels - list of node labels that are used in the index. Only properties of nodes with these labels will be indexed. Changing this list will result in the requirement to reindex the database.
Indexed types - list of relationship types that are used in the index. Only properties of relationships with these types will be indexed. Changing this list will result in the requirement to reindex the database.
Text analyzer - analyzer used for creating the index in Neo4j. Changing the analyzer will change the search experience. For instance, some of the analyzers are case-sensitive, some of them have specific stop words for certain languages, etc.
Minimal steps to set up the Fulltext index:
Choose "Indexed properties" for nodes and relationships - only values from these properties will be searchable.
Choose "Indexed labels" and “Indexed types“ (or check the "Use all labels" or “Use all types“ checkboxes) - only nodes/relationships with at least one of these labels/types will be searchable.
If the configuration values have been changed a reindex is needed. Click on the "Start reindex" button to start reindexing (this can take a while depending on the number of nodes/relationships and the number of indexed properties).
Note: Graphlytic is automatically creating and maintaining fulltext indexes with the names "gl_fulltext_node_index" and “gl_fulltext_relationship_index“.
After successful reindexing, the Status should be "Online".
2.3. Gremlin Search
Search is performed directly in the graph DB using pure Gremlin value matching. This is a very basic search option with multiple limitations:
full-scan of the graph is performed - can be very slow on larger graphs
case-sensitive search - values have to be entered precisely as they are stored in the graph
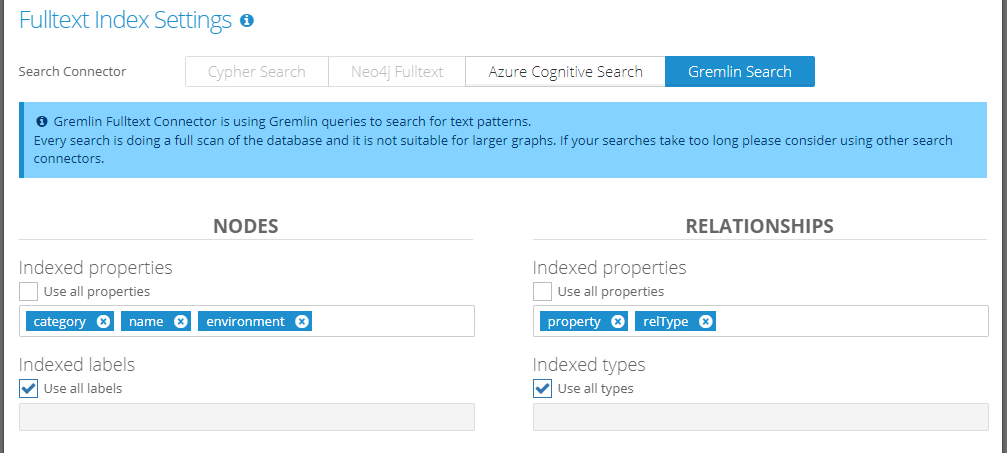
Parts of the configuration:
Indexed properties - list of properties used in the search query. Please choose the list carefully. Keeping the number of indexed properties reasonably low (e.g. 2 - 10 properties) can speed up the search.
The checkbox “Use all properties” can be used to automatically search using all properties in the graph.
Indexed labels - list of node (vertex) labels that are used in the search query. Only properties of nodes with these labels will be searched.
The checkbox “Use all labels” can be used to automatically search using all node labels in the graph.
Indexed types - list of relationship (edge) types that are used in the search query. Only properties of relationships with these types will be searched.
The checkbox “Use all types” can be used to automatically search using all relationship types in the graph.
2.4. Azure Cognitive Search
Uses Azure Cognitive Search as an external search engine. Data has to be periodically imported into the Azure Cognitive Search service to ensure consistency between your graph DB and search indexes (Graphlytic is not doing this out of the box, the connection and data importing have to be done by the user). This search connector is best with Cosmos DB because Azure has multiple tools how to easily connect Cosmos DB and Azure Cognitive Search.
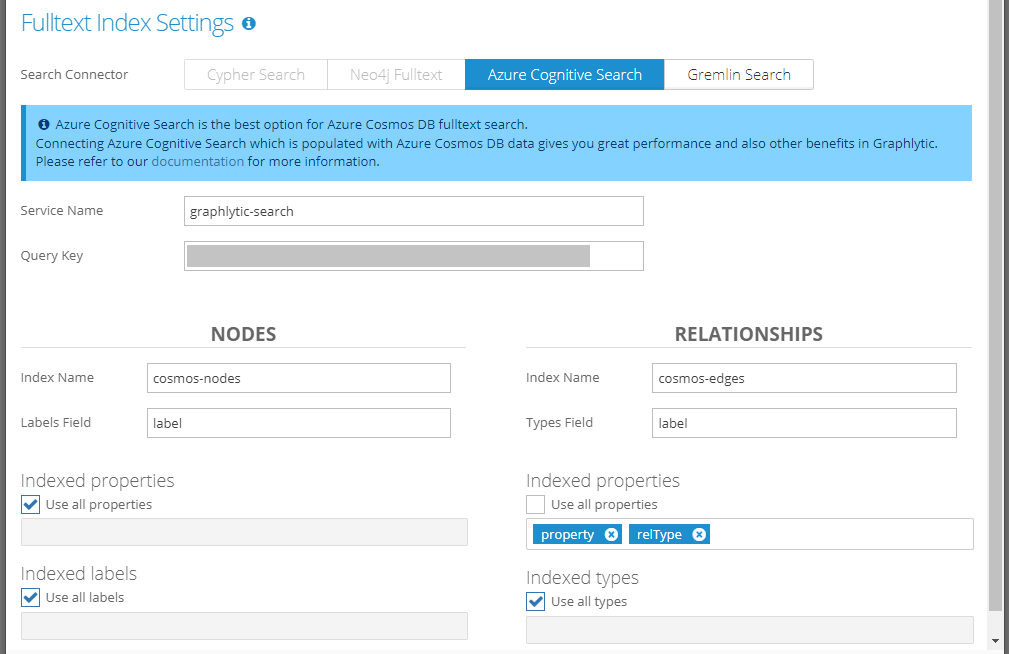
Parts of the configuration:
Service Name - Name of the Azure Cognitive Search service that should be used for the fulltext search.
Query Key - Azure Cognitive Search query key (refer to the next chapter for more information on how to obtain the key).
Nodes
Index Name - Name of the index in Azure Cognitive Search that should be used for node searching.
Labels Field - Field in the index with node label values.
Indexed properties - Properties that will be used in the fulltext search query.
Indexed labels - Node labels that will be used in the fulltext search query.
Relationships
Index Name - Name of the index in Azure Cognitive Search that should be used for relationship searching.
Types Field - Field in the index with relationship type values.
Indexed properties - Properties that will be used in the fulltext search query.
Indexed types - Relationship types that will be used in the fulltext search query.
2.4.1. How to configure Azure Cognitive Search with Azure Cosmos DB
Steps to connect Cosmos DB to Azure Cognitive Search and indexes configuration:
Create Azure Cognitive Search service - if you don’t have the Azure Cognitive Search service created, please follow the instructions in the Azure portal - https://azure.microsoft.com/en-us/products/search/
Add new Data Sources - create two data sources connected to your Cosmos DB - one for nodes (vertices) and one for relationships (edges). Tip: Use “Choose an existing connection” to easily select your Cosmos DB.
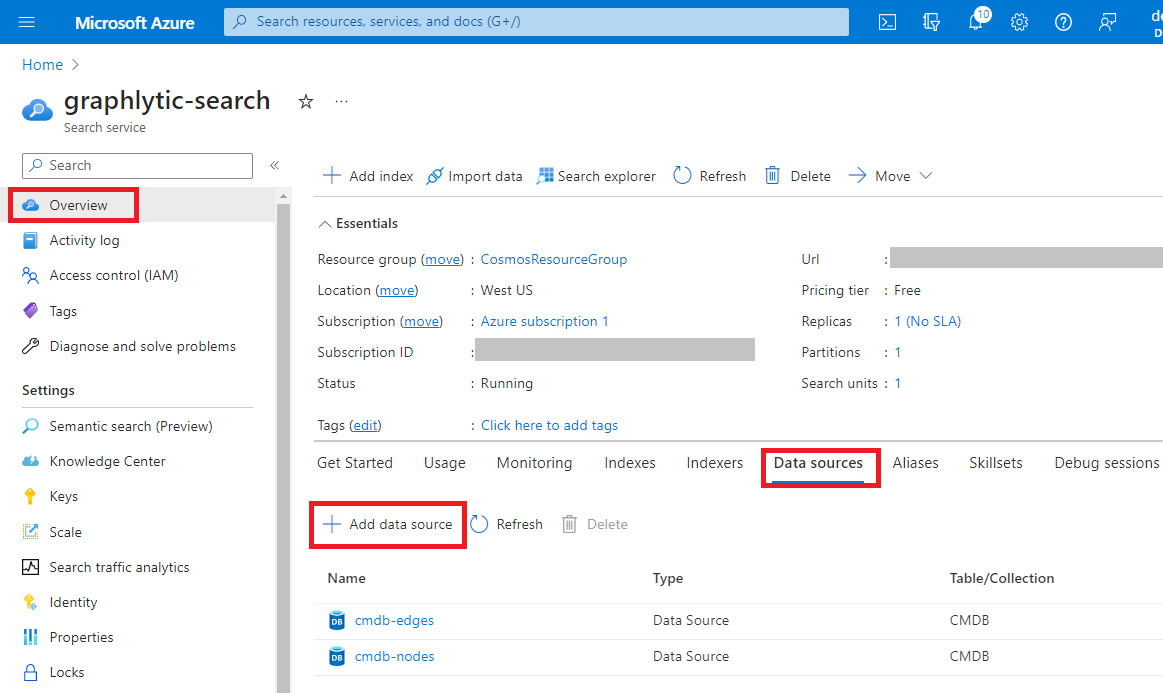
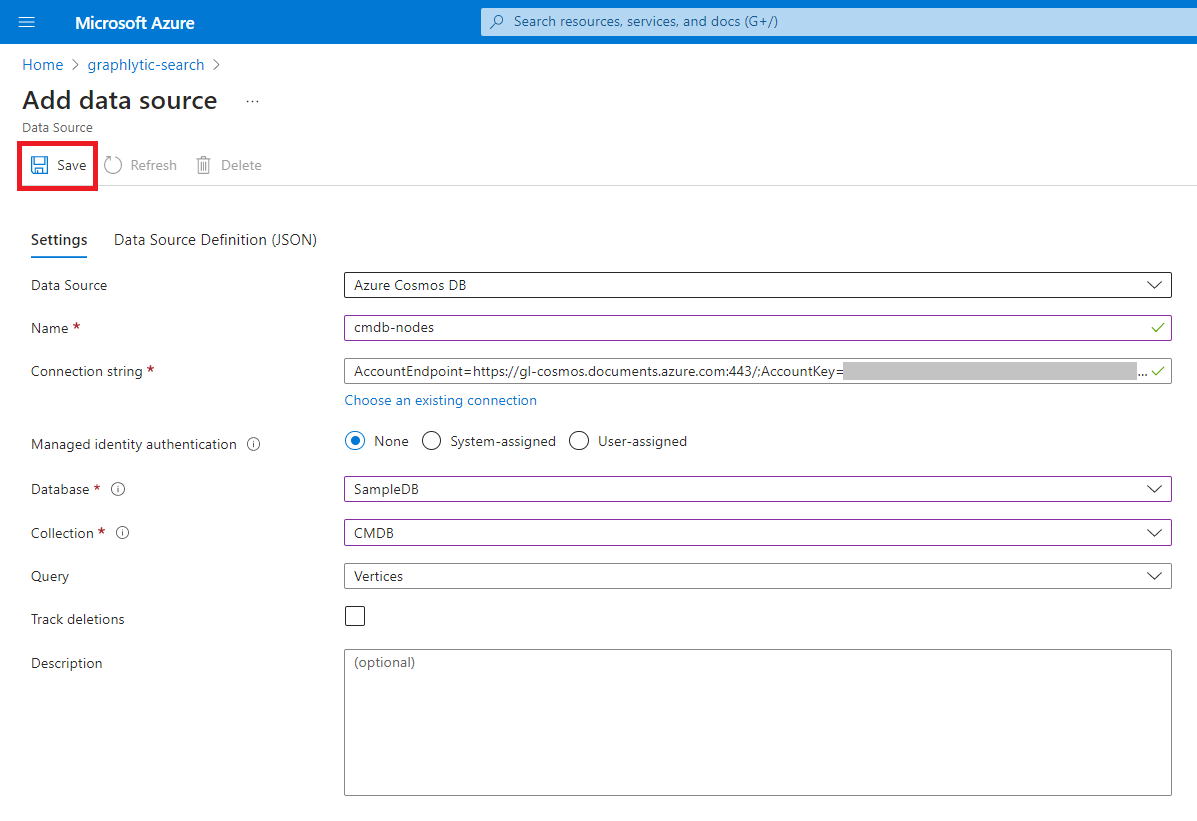
3. Add Indexes - create two indexes - one for nodes (vertices) and one for relationships (edges). Add all properties that should be searchable to the indexes. Example of a node index configuration is in the picture below.
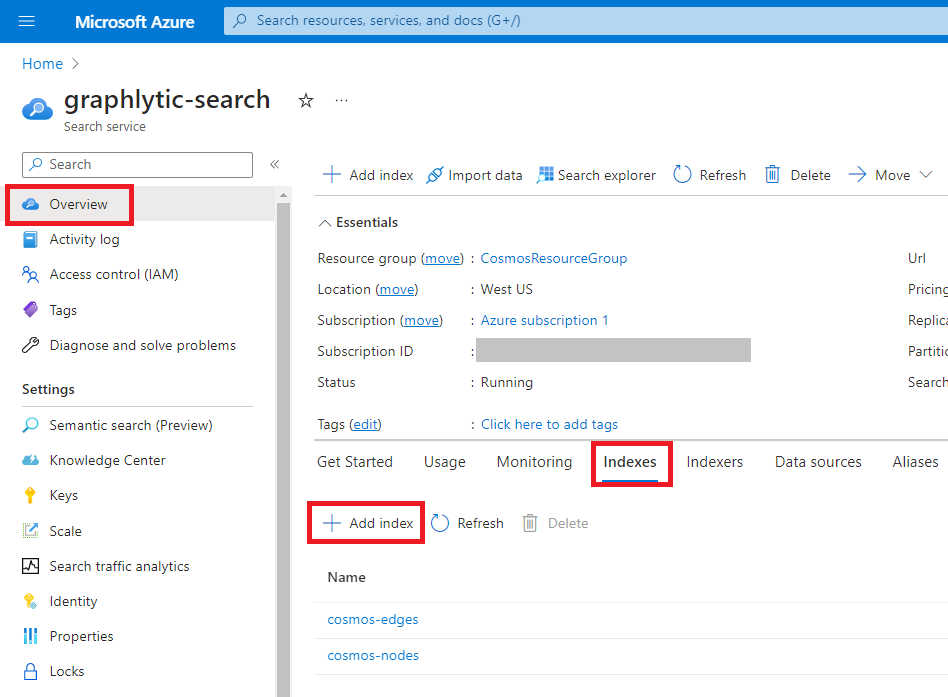
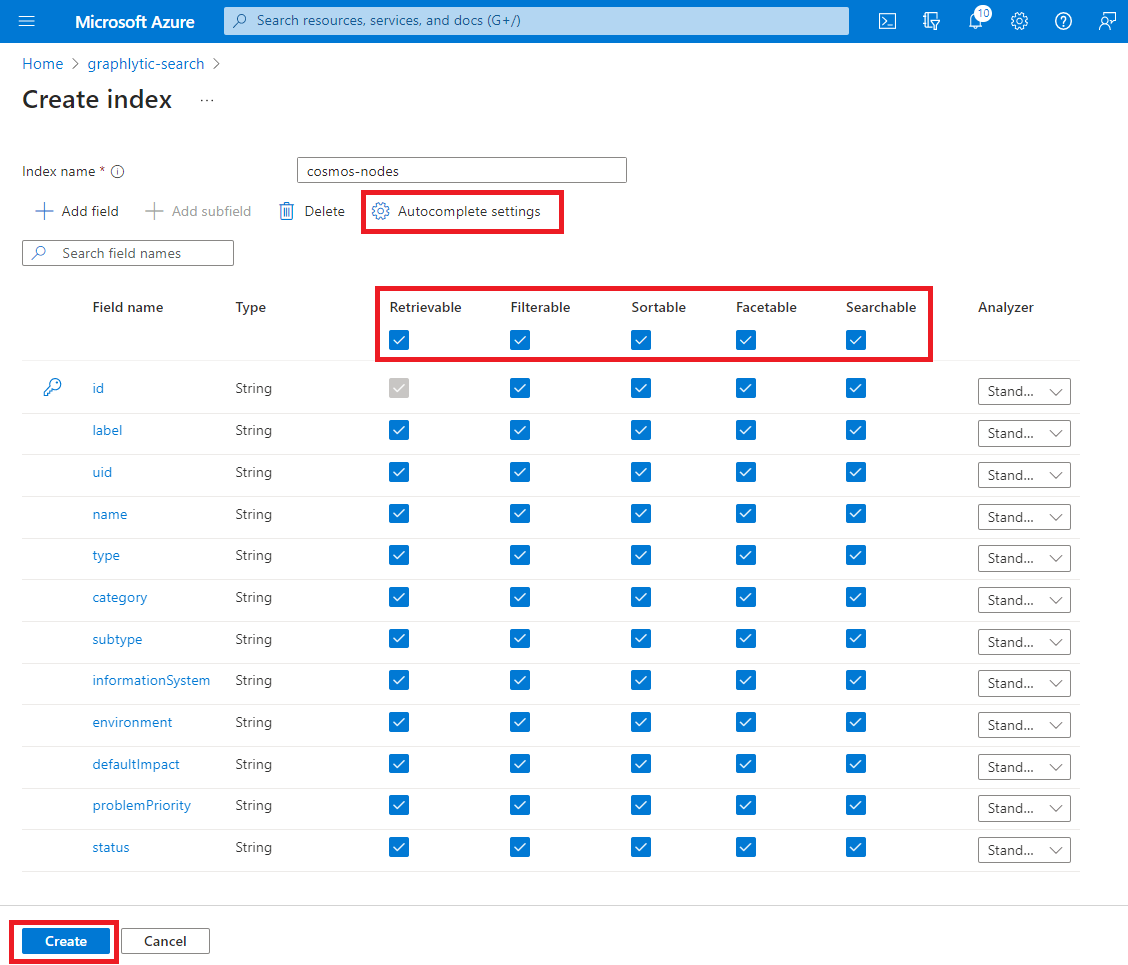
4. Add Indexers - Indexers are automatic jobs that are importing data from Cosmos DB into the Azure Cognitive Search indexes. Create two Indexers - one for nodes (vertices) and one for relationships (edges). Example of an indexer configuration in in picture below.
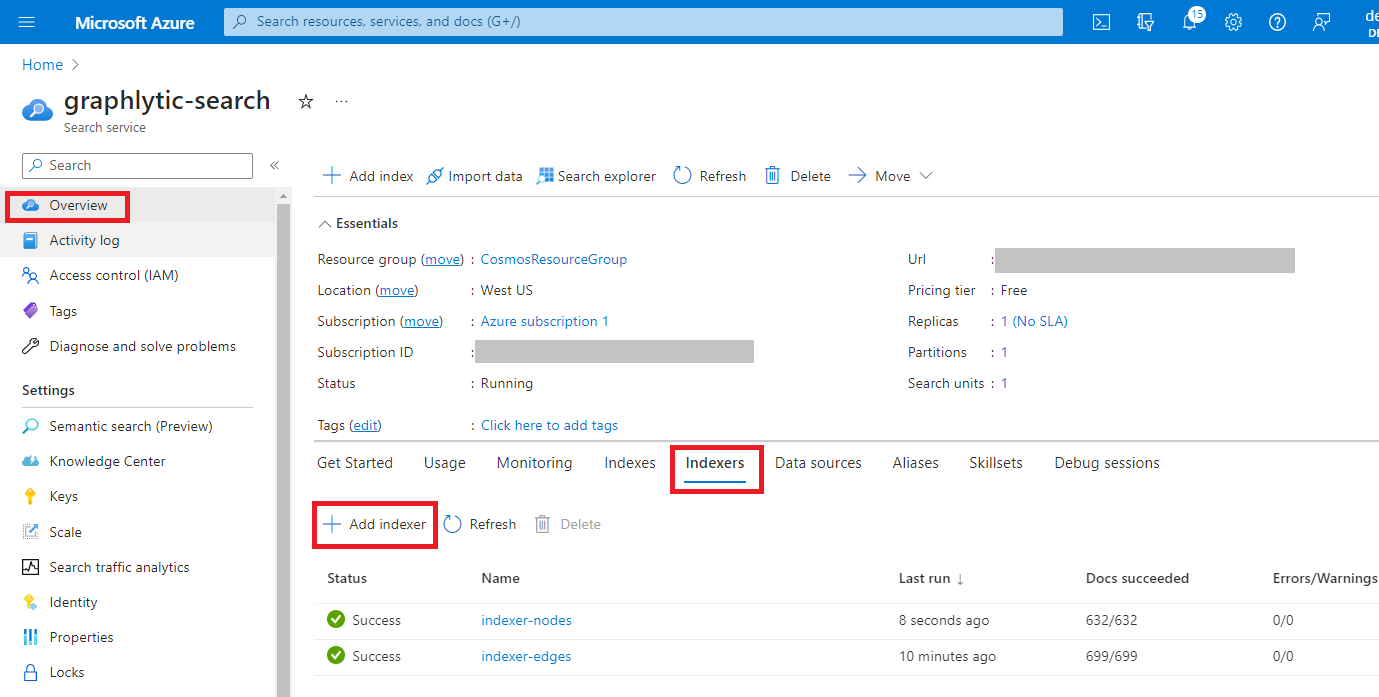
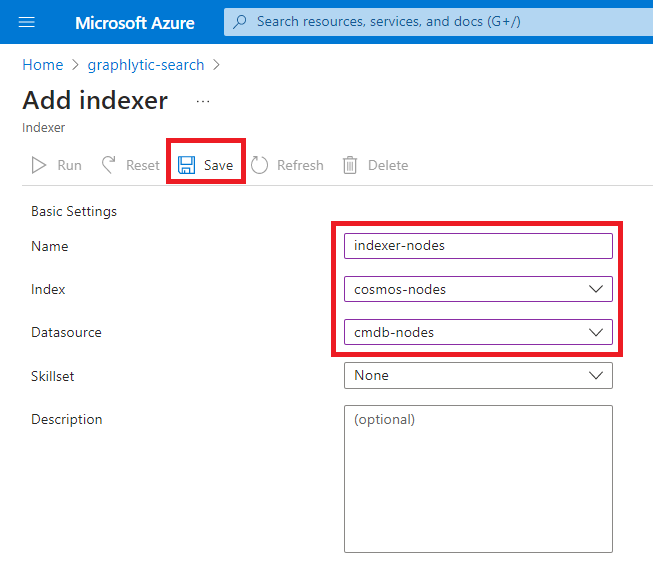
5. Configure fulltext search in Graphlytic - use indexes created in Azure Cognitive Search in Graphlytic fulltext search configuration.
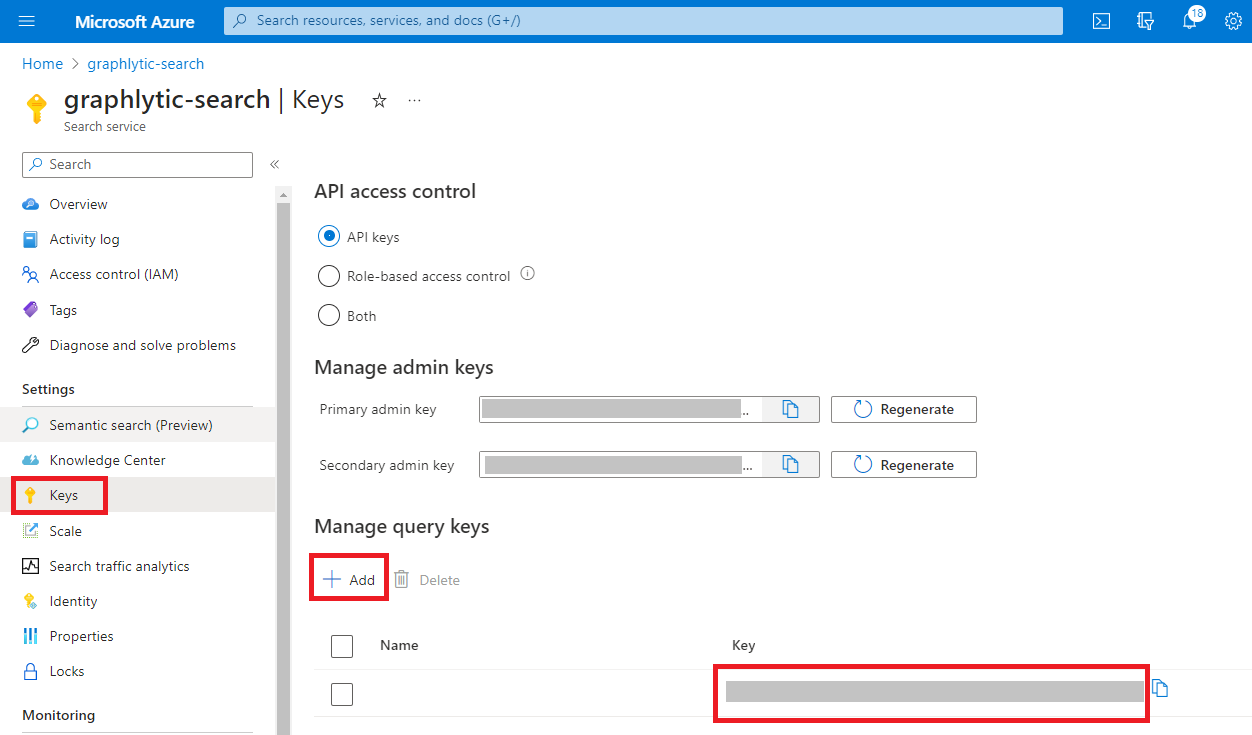
Where to find the Query key in Azure? Go to the Keys page and create a query key that can be used in Graphlytic.